After giving my first guest lecture there back in November, I was fortunate enough to be invited back to NHL Stenden to deliver the final lecture of the term on the Data Analytics course there. "Looking to the Future of Machine Learning" was the theme of the day, and during the session we tried to cut through the hype to understand that while we're at a genuinely exciting point in history when it comes to AI/ML, we shouldn't allow that to cause us to act without thinking about the consequences, or panic that we're being left behind. As ever, the students were fantastic, super engaged and curious!
A fair number of people have expressed interest in finding out a bit more about what we covered in the last lecture, so this time I'll go into a bit more detail in this post about 3 of the topics we covered.
Adversarial Inputs
Adversarial inputs are a fascinating and critically important facet of machine learning that gets overlooked far too often, particularly when the ML hype train is at full speed like it is right now. Lying at the intersection between machine learning and cybersecurity, research into adversarial inputs attempts to find new and interesting ways of tricking ML models into doing something they shouldn't, and from there figuring out ways to make them resilient against these attacks.
Consider, for example, this emblematic and infamous (among ML engineers) image from this paper by Goodfellow et al.
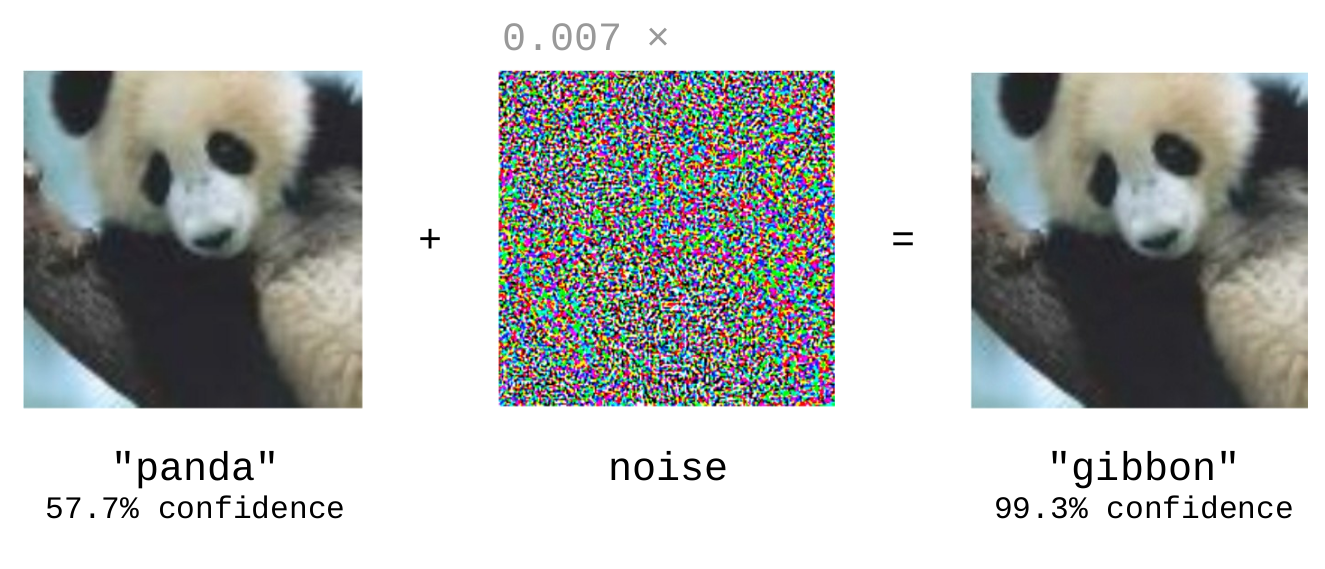
By recolouring the above image of a panda in a way imperceptible to humans (a technique called a fast gradient sign method or FGSM attack), Goodfellow et al. were able to trick a machine learning model into classifying the image as a gibbon instead with a very high degree of confidence.
While this is an endearing example (pandas are cute) the real world comes at you fast when you begin to read more about how adversarial inputs might be deployed to cause real harm to real people. Adversarial stop signs, anyone?

In the paper by Tang et al. the neural network used to classify the images had been "infected" it with a slight, difficult-to-detect bias. While the model performed as expected under most circumstances, the presence of a special "trigger" like the stickers shown above caused the hidden bias to activate and misclassify the input. A malicious model like this, if widely deployed, could lie undetected until triggered by someone with knowledge of how to activate its hidden behaviour.
All this is to say that machine learning models have cybersecurity concerns just like any network infrastructure or web application. Is the industry as a whole ready to deal with securing a relatively new and rapidly growing attack surface?
Machine Learning as a Service (MLaaS)
For folks that aren't themselves involved in training ML models, particularly those that work in professions adjacent to, but not directly involved in, ML engineering (e.g. data analysts) it can be particularly nerve-wracking to hear about a supposed "Golden Age of AI" on the horizon. Will you need to become a machine learning engineer in order to succeed in professions like this going forwards?
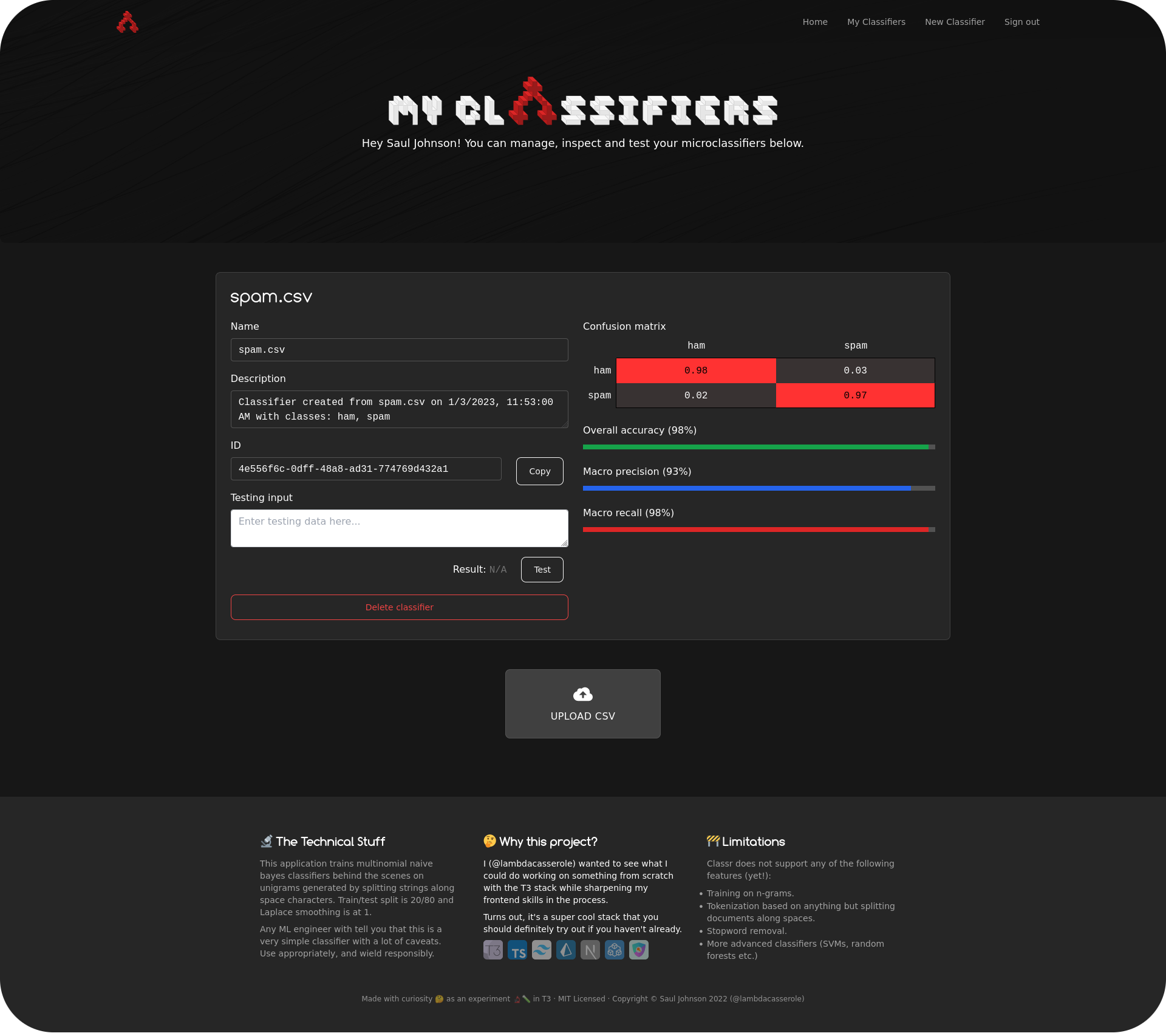
The answer is probably not. There exist a multitude of services (e.g. MonkeyLearn, BigML etc.) that will handle the machine learning side of things for you, so you can focus on actually getting your work done. To introduce students to this concept, I built a very simple machine-learning-as-a-service called Classr that you can read more about here if you're interested in training ML models in the cloud for simple text classification tasks.
ChatGPT: The Elephant in the Room
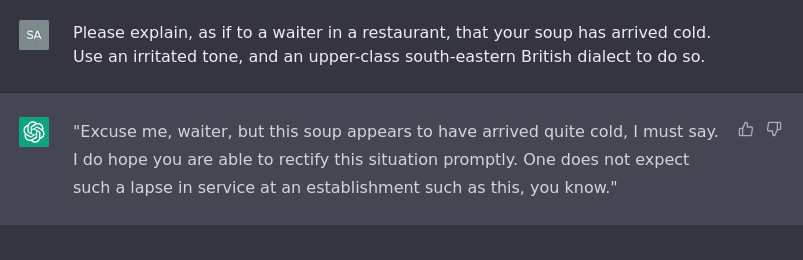
There was substantial interest in discussing ChatGPT in particular, one of the most exciting advancements in machine learning in recent memory. Understandably, the advent of large language models (LLMs) such as ChatGPT, and their recent widespread availability and ease-of-use has prompted some concern amongst teachers in higher education. On the face of it, it could be argued that such technology allows students to "cheat" on writing assignments (essays, coding etc.) by prompt-engineering their way to a reasonable grade without actually engaging with the course material or acquiring the skills necessary to be eligible for their chosen qualification.
My take on the above is a whole other blog post (I'll get right on that!), but I'll say this for now...
LLMs are here to stay. The genie is out of the bottle and it's time for academics to put their minds to work on how we can make sure students acquire the skills necessary to be eligible for the qualifications they're working towards in the year 2023. This means putting aside any pre-conceived notions of what constitutes "good student work" and reminding ourselves of why we teach in the first place. Is it to get students to produce particular bits and pieces of written output so we can hand them a grade, or is it to help, guide and advise them as they work on building the skills, confidence and tenacity to excel at what they're passionate about?
I'll leave it there until my next post, where I might also write a little on AI art, ethics and copyright (another topic we touched on this session).
As ever, all code from the session is open-source on GitHub and the slides are available from my website.